%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Diffusion Model

Dream 7B
Dream 7B is the latest diffusion large language model jointly launched by the NLP group of the University of Hong Kong and Huawei Noah's Ark Lab. It demonstrates excellent performance in text generation, especially in complex reasoning, long-term planning, and contextual coherence. The model adopts advanced training methods, possesses strong planning capabilities and flexible reasoning capabilities, and provides stronger support for various AI applications.
AI Model
41.7K

Accvideo
AccVideo is a novel and efficient distillation method that accelerates the inference speed of video diffusion models through synthetic datasets. This model can achieve an 8.5-fold speed improvement in video generation while maintaining similar performance. It uses a pre-trained video diffusion model to generate multiple effective denoising trajectories, thereby optimizing data usage and the generation process. AccVideo is especially suitable for scenarios requiring efficient video generation, such as film production and game development, and is suitable for researchers and developers.
Video Production
65.1K
Trajectorycrafter
TrajectoryCrafter is an advanced camera trajectory redirection tool that utilizes diffusion model technology to redesign the camera movement in monocular videos, enhancing the expressiveness and visual appeal of the video. This technology can be widely applied in film production and virtual reality fields, featuring efficiency, convenience, and innovation, aiming to provide users with more creative freedom and control.
Video Editing
45.8K
English Picks
Inception Labs
Inception Labs is a company focused on developing diffusion-based large language models (dLLMs). Its technology is inspired by advanced image and video generation systems such as Midjourney and Sora. Through diffusion models, Inception Labs offers speeds 5-10 times faster than traditional autoregressive models, higher efficiency, and stronger generative control. Its models support parallel text generation, can correct errors and hallucinations, are suitable for multimodal tasks, and excel in reasoning and structured data generation. The company is composed of researchers and engineers from Stanford, UCLA, and Cornell University and is a pioneer in the field of diffusion models.
AI Model
67.9K
Project Starlight
Project Starlight is an AI video enhancement model launched by Topaz Labs, designed to improve the quality of low-resolution and damaged videos. It uses diffusion model technology to achieve video super-resolution, noise reduction, deblurring, and sharpening, while maintaining temporal consistency to ensure smooth transitions between video frames. This technology is a significant breakthrough in the field of video enhancement, bringing unprecedented high-quality results to video repair and enhancement. Currently, Project Starlight offers a free trial and plans to support 4K export in the future, primarily targeting users and enterprises who need high-quality video repair and enhancement.
Video Editing
48.3K
English Picks
Mercury Coder
Mercury Coder is Inception Labs' first commercially available diffusion large language model (dLLM), optimized for code generation. This model uses diffusion model technology, employing a 'coarse-to-fine' generation method to significantly improve generation speed and quality. It's 5-10 times faster than traditional autoregressive language models, achieving generation speeds exceeding 1000 tokens per second on NVIDIA H100 hardware while maintaining high-quality code generation. This technology addresses the bottlenecks of current autoregressive language models in generation speed and inference cost. Mercury Coder overcomes these limitations through algorithmic optimization, providing a more efficient and cost-effective solution for enterprise applications.
Coding Assistant
81.7K
Videograin
VideoGrain is a diffusion model-based video editing technology that achieves multi-granularity video editing by adjusting the spatiotemporal attention mechanism. This technology addresses the issues of semantic alignment and feature coupling in traditional methods, enabling fine-grained control over video content. Its key advantages include zero-shot editing capabilities, efficient text-to-region control, and feature separation capabilities. This technology is suitable for scenarios requiring complex video editing, such as post-production in film and television and advertising production, significantly improving editing efficiency and quality.
Video Editing
51.1K
Makeanything
MakeAnything is a diffusion transformer-based model focused on multi-domain procedural sequence generation. By combining advanced diffusion models and transformer architecture, it can generate high-quality, step-by-step creative sequences, such as paintings, sculptures, icon designs, and more. Its main advantage lies in its ability to handle generative tasks across multiple domains and quickly adapt to new domains with a small number of samples. Developed by the Show Lab team at the National University of Singapore, this model is currently available as open-source, aiming to promote the development of multi-domain generation technology.
AI design tools
55.5K
Pippo
Pippo, developed in collaboration between Meta Reality Labs and various universities, is a generative model capable of producing high-resolution, multi-view videos from a single ordinary photograph. Its core advantage lies in generating high-quality 1K resolution videos without any additional input (such as parameterized models or camera parameters). Based on a multi-view diffusion transformer architecture, it has broad application prospects in areas like virtual reality and film production. Pippo's code is open-source, but pre-trained weights are not included; users need to train the model themselves.
Video Production
104.9K
X Dyna
X-Dyna is an innovative zero-shot human image animation generation technology that creates realistic and expressive dynamic effects by transferring facial expressions and body movements from a driving video to a single human image. This technology uses a diffusion model and integrates reference appearance context effectively into the diffusion model's spatial attention through the Dynamics-Adapter module, while maintaining the motion module's ability to synthesize smooth and complex dynamic details. It not only enables body posture control but also captures and precisely transfers identity-independent facial expressions through a local control module. Trained on mixed datasets of various human and scene videos, X-Dyna can learn physical human motions and natural scene dynamics, generating highly realistic and expressive animations.
Video Production
48.0K
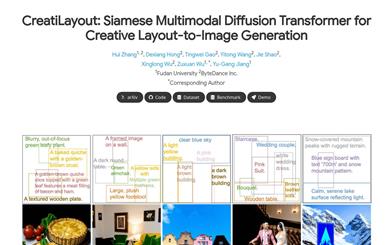
Creatilayout
CreatiLayout is an innovative layout-to-image generation technology that employs the Siamese Multimodal Diffusion Transformer to achieve high-quality, finely controlled image outputs. This technology can accurately render complex attributes such as color, texture, shape, quantity, and text, making it suitable for applications that demand precise layout and image generation. Its primary benefits include efficient layout-guided integration, powerful image generation capabilities, and support for large-scale datasets. CreatiLayout is jointly developed by Fudan University and ByteDance, aimed at promoting the application of image generation technology in the creative design field.
AI design tools
60.2K

Colorflow
ColorFlow is a model designed for coloring image sequences, with a particular focus on preserving the identity of characters and objects during the coloring process. Utilizing contextual information, it accurately generates colors for different elements (such as hair and clothing) in black-and-white image sequences based on a pool of reference images, ensuring consistency with the color references. Through a three-phase diffusion model framework, ColorFlow introduces a novel retrieval-augmented coloring workflow that achieves relevant image coloring without the need for fine-tuning each identity or extracting explicit identity embeddings. Its main advantages include high-quality coloring effects while retaining identity information, which is of significant market value for coloring cartoon or comic series.
Image Editing
50.5K

Anchorcrafter
AnchorCrafter is an innovative diffusion model system designed to generate 2D videos that include target characters and customized objects, achieving high visual fidelity and controllable interactions through the integration of human-object interaction (HOI). The system enhances the ability to recognize object appearances from arbitrary viewpoints through HOI-appearance perception and separates the appearances of humans and objects. HOI-motion injection overcomes challenges in managing object trajectory conditions and occlusions, enabling complex human-object interactions. Furthermore, the reweighted loss for HOI areas serves as a training objective to enhance the learning of object details. This technology is significant to fields such as online commerce, advertising, and consumer engagement, maintaining the consistency of human appearance and movement while preserving the awareness of object appearance and shape.
Video Production
219.4K
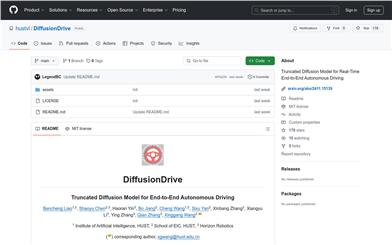
Diffusiondrive
DiffusionDrive is a truncated diffusion model designed for real-time end-to-end autonomous driving. It accelerates computation speed by reducing diffusion denoising steps while maintaining high accuracy and variability. The model learns directly from human demonstrations, enabling real-time driving decisions without complex preprocessing or postprocessing steps. DiffusionDrive achieved a groundbreaking result of 88.1 PDMS on the NAVSIM benchmark and can operate at 45 FPS.
AI Model
48.0K
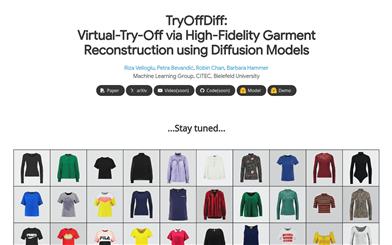
Tryoffdiff
TryOffDiff is a high-fidelity garment reconstruction technology that generates standardized garment images from a single photo of an individual wearing clothing. Unlike traditional virtual try-ons, this technology aims to extract normative garment images, which poses unique challenges in capturing garment shape, texture, and complex patterns. TryOffDiff ensures high fidelity and detail retention by utilizing Stable Diffusion and SigLIP-based visual conditions. Experiments on the VITON-HD dataset demonstrate that its approach outperforms baseline methods based on pose transfer and virtual try-on while requiring fewer preprocessing and postprocessing steps. TryOffDiff not only enhances the quality of e-commerce product images but also advances the evaluation of generative models and inspires future work in high-fidelity reconstruction.
AI design tools
75.1K
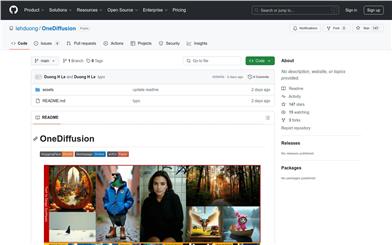
Onediffusion
OneDiffusion is a versatile, large-scale diffusion model capable of seamlessly supporting bidirectional image synthesis and understanding across a variety of tasks. The model is expected to release its code and checkpoints in early December. The significance of OneDiffusion lies in its ability to handle tasks related to image synthesis and understanding, marking an important advancement in the field of artificial intelligence, especially in image generation and recognition. Background information indicates that this is a collaborative project developed by multiple researchers, and the research outcomes have been published on arXiv.
Image Generation
51.6K
Joyvasa
JoyVASA is an audio-driven character animation technique based on diffusion models that generates facial dynamics and head movements by separating dynamic facial expressions from static 3D facial representations. This technology enhances video quality and lip-sync accuracy, expands into animal facial animation, supports multiple languages, and improves training and inference efficiency. Key advantages of JoyVASA include the ability to generate longer videos, motion sequence generation independent of character identity, and high-quality animation rendering.
Audio-Driven
60.2K

Fashion VDM
Fashion-VDM is a video diffusion model (VDM) designed to generate virtual try-on videos. This model accepts an image of a garment and a video of a person as input, aiming to produce high-quality videos showcasing the person wearing the specified clothing while preserving their identity and movements. Compared to traditional image-based virtual try-on, Fashion-VDM excels in garment detail and temporal consistency. The main advantages of this technology include: a diffusion architecture, classifier-free guidance enhancing control, progressive temporal training strategies for generating 64-frame 512px videos in one pass, and the effectiveness of joint image-video training. Fashion-VDM sets a new industry standard in the realm of video virtual try-on.
Video Production
99.6K
Mardini
MarDini is a video diffusion model launched by Meta AI Research, integrating the advantages of Masked Auto-Regressive (MAR) within a unified Diffusion Model (DM) framework. This model enables video generation at any frame position based on any number of masked frames, supporting various video generation tasks such as video interpolation, image-to-video generation, and video extension. MarDini is designed to allocate most computational resources to a low-resolution planning model, making large-scale space-time attention feasible. MarDini sets new benchmarks in video interpolation and efficiently generates videos comparable to more costly advanced image-to-video models within a few inference steps.
Video Production
48.0K
Genmoai
genmoai/models is an open-source video generation model representing the latest advancements in video generation technology. Named Mochi 1, it is a billion-parameter diffusion model based on the Asymmetric Diffusion Transformer (AsymmDiT) architecture, trained from scratch. It is currently the largest publicly released video generation model to date, offering high fidelity motion and strong adherence to prompts, significantly narrowing the gap between closed and open video generation systems. The model is released under the Apache 2.0 license, allowing users to try it out for free on Genmo's playground.
Video Production
52.2K
Stable Diffusion 3.5 Large
Stable Diffusion 3.5 Large is a multi-modal diffusion transformer (MMDiT) model developed by Stability AI for generating images from text. The model shows significant improvements in image quality, layout, understanding complex prompts, and resource efficiency. It employs three fixed pretrained text encoders and enhances training stability through QK normalization techniques. Additionally, the model utilizes synthesized and filtered publicly available data in its training data and strategies. The Stable Diffusion 3.5 Large model is free for research, non-commercial use, and commercial use for organizations or individuals with annual revenues under $1 million, in compliance with community licensing agreements.
Image Generation
59.3K

ACE: All Round Creator And Editor Following Instructions Via Diffusion Transformer
ACE is a diffusion transformer-based all-in-one creator and editor that facilitates joint training of multiple visual generation tasks using a unified input format known as Long-context Condition Unit (LCU). ACE addresses the challenge of insufficient training data through efficient data collection methods and generates accurate textual instructions using multimodal large language models. It demonstrates significant performance advantages in the realm of visual generation, enabling the creation of chat systems that seamlessly respond to any image creation request, thus circumventing the cumbersome workflows typically employed by visual agents.
AI image generation
53.3K
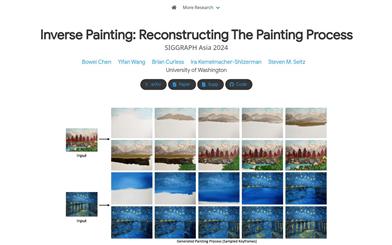
Inverse Painting
Inverse Painting is a diffusion model-based method that generates time-lapse videos of the painting process from a target artwork. This technique learns from the painting processes of real artists through training, capable of handling various artistic styles and creating videos that resemble the painting process of human artists. It integrates text and region understanding, defining a set of painting instructions, and utilizes a novel diffusion-based renderer to update the canvas. The technology not only manages a limited range of acrylic painting styles during training but also provides reasonable results across a broad spectrum of artistic styles and genres.
AI image generation
119.0K
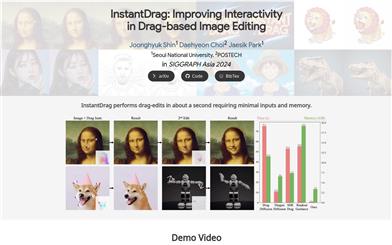
Instantdrag
InstantDrag is an optimized process that enhances interactivity and speed by using only images and drag instructions as input. This technology consists of two carefully designed networks: the drag-condition optical flow generator (FlowGen) and the motion-conditioned diffusion model (FlowDiffusion). InstantDrag learns the motion dynamics of drag image editing based on real-world video datasets by breaking down tasks into motion generation and motion-conditioned image generation. It can quickly perform realistic edits without requiring masks or text prompts, making it a promising solution for interactive, real-time applications.
Image Editing
52.2K

Generative Keyframe Interpolation With Forward Backward Consistency
This product is an image-to-video diffusion model that can generate continuous video sequences with coherent motion from a pair of keyframes through lightweight fine-tuning techniques. This method is particularly suitable for scenarios requiring smooth transitional animation between two static images, such as animation production and video editing. It harnesses the powerful capabilities of large-scale image-to-video diffusion models by fine-tuning them to predict the video between two keyframes, ensuring forward and backward consistency.
AI video generation
57.1K
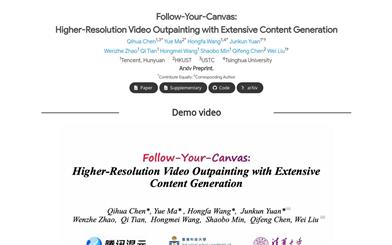
Follow Your Canvas
Follow-Your-Canvas is a video upscaling technology based on a diffusion model that can generate high-resolution video content. This technology addresses GPU memory limitations through distributed processing and spatial window merging while maintaining both spatial and temporal consistency in the video. It excels in large-scale video upscaling, significantly enhancing video resolution (e.g., from 512 x 512 to 1152 x 2048) while delivering high-quality and visually pleasing results.
AI video generation
50.2K

Texgen
TexGen is an innovative multi-view sampling and resampling framework for synthesizing 3D textures from arbitrary textual descriptions. It leverages a pre-trained text-to-image diffusion model, implementing consistent view sampling and attention-guided multi-view sampling strategies, along with noise resampling techniques, to significantly enhance the texture quality of 3D objects, achieving high viewpoint consistency and rich appearance details.
AI image generation
61.3K
Catvton
CatVTON is a virtual try-on technology based on a diffusion model, featuring a lightweight network (total of 899.06M parameters), parameter-efficient training (49.57M trainable parameters), and simplified inference (less than 8G VRAM at 1024X768 resolution). By streamlining the network structure and inference process, it achieves quick and effective virtual fitting results, making it particularly suitable for the fashion industry and personalized recommendation scenarios.
AI Try-on
145.5K
Rodinhd
RodinHD is a high-fidelity 3D avatar generation technology based on diffusion models, developed by researchers including Bowen Zhang and Yiji Cheng. It aims to generate detailed 3D avatars from a single portrait image. This technology addresses the shortcomings of existing methods in capturing complex details such as hairstyles by employing novel data scheduling strategies and weight integration regularization terms, improving the decoder's ability to render sharp details. Additionally, it optimizes the guiding effect of portrait images through multi-scale feature representation and cross-attention mechanisms, resulting in 3D avatars with significantly enhanced detail compared to previous methods. Notably, it also exhibits strong generalization capabilities to wild portrait inputs.
AI head image generation
112.1K
Asyncdiff
AsyncDiff is a method for accelerating diffusion models through asynchronous denoising parallelization. It divides the noise prediction model into multiple components and distributes them across different devices, enabling parallel processing. This approach significantly reduces inference latency while having a minimal impact on generation quality. AsyncDiff supports a variety of diffusion models, including Stable Diffusion 2.1, Stable Diffusion 1.5, Stable Diffusion x4 Upscaler, Stable Diffusion XL 1.0, ControlNet, Stable Video Diffusion, and AnimateDiff.
AI image generation
51.9K
- 1
- 2
- 3
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M